
go对我而言其最令人激动的地方就是接口的设计,例如静态类型、编译时检查。如果非要让我将go的一个特性运用到其它语言的设计当中,那一定非接口莫属。
这篇文章描述了我对接口值在“ GC ”的编译器的实现。 Ian Lance Taylor已经写了两篇关于接口值在gccgo中如何实现的文章。这篇文章与其大同小异:最大的区别是,本文有图片。
Usgae
go接口的使用让你感觉像是在用python这样纯粹的动态语言一样,但不同的是仍然有编译器帮你进行静态检查,例如传了一个int型变量给Read方法,或者给Read方法传了错误的参数个数。要使用go的接口,首先得定义一个接口类型(比如下面的ReadCloser)1
2
3
4type ReadCloser interface {
Read(b []byte) (n int, err os.Error)
Close()
}
然后定义一个带有ReadCloser参数的函数。例如,下面这个函数通过循环调用Read方法获取所有的请求数据,然后再调用Close方法1
2
3
4
5
6
7
8
9
10func ReadAndClose(r ReadCloser, buf []byte) (n int, err os.Error) {
for len(buf) > 0 && err == nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:]
}
r.Close()
return
}
调用ReadAndClose函数的时候,只要任何实现了Read和Close方法的类型,都可以作为该函数的第一个参数传递进去。而且不像python,如果你传递了一个错误的类型,那么编译器就会报告类型错误,而不是等到运行时才报错。
当然,接口并不局限于静态检查,你也可以在运行时动态的检查一个接口的实际类型。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16type Stringer interface {
String() string
}
func ToString(any interface{}) string {
if v, ok := any.(Stringer); ok {
return v.String()
}
switch v := any.(type) {
case int:
return strconv.Itoa(v)
case float:
return strconv.Ftoa(v, 'g', -1)
}
return "???"
}
any参数的类型是interface{},即该接口没有任何的方法,这意味着它可以接收任何类型的参数。在if语句中的”comma ok”表达式尝试将any转成Stringer接口类型,这个接口类型包含了String方法,如果转换成功,在if的中括号内,将调用String方法获取字符串值并返回回去。如果转换失败,在接下来的的switch语句中,又验证了了两个基础类型。这个函数就像是fmt包的一个精简版的实现。(这里那个if语句实际上可以转化为case Stringer放到swtich顶部中去,这里为了演示故意写成这样)
举一个简单的例子:考虑定义一个底层类型为unit64的Binary类型,并为它写一个String()方法和Get()方法1
2
3
4
5
6
7
8
9type Binary uint64
func (i Binary) String() string {
return strconv.Uitob64(i.Get(), 2)
}
func (i Binary) Get() uint64 {
return uint64(i)
}
假设将类型为Binary的值传给ToString函数,那么在ToString内部将调用String方法并返回。在程序运行的过程中,运行时知道Binary类型有String方法,所以,程序认为它实现了Stringer接口。这是一种奇妙的设计,因为有时候甚至连Binary的作者都不知道Stringer接口的存在。
以上这些例子表明即使所有的隐式转换是在编译时进行检查,显示的接口到接口的转换也可以在运行时进行。Effective Go有更多关于接口的详细例子。
Interface Values
拥有方法的语言通常分为两大阵营:
- 拥有方法表的静态语言(如C++和Java)
- 每次调用都进行方法地址查询的动态语言(如Smalltalk和它的众多模仿者、javascript和python等,有的会通过缓存提高它调用的效率)。
Go则位于两者的中间,它拥有方法表,但却是在运行时计算它们。我不知道go是不是第一个使用该技术的语言,但这种方式肯定是不常见的。
举个例子,一个Binary类型的值是一个64位整型,它由两个32位的字组成(假设我们现在使用的是32位的机器)

Interface由两个字长组成,其中一个存储指向接口类型表的指针,另一个存储指向数据的指针。如果将b赋值给一个Stringer类型的接口变量,其内存结构如下图所示
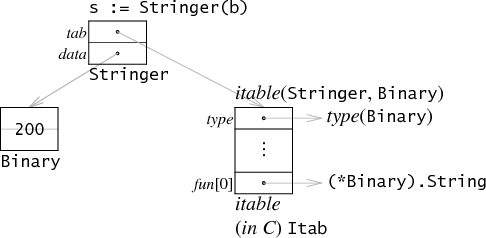
(接口中存储的指针对程序是不可见的,它不会直接暴露给用户)
第一个字节中的指针指向一个名字叫作itable的内存块(在C中叫作Itab)。itable头部存储了一些与类型相关的元数据,然后才是函数指针列表。itable对应的是接口类型,而不是动态类型。以我们的例子来讲,Stringer的itable保存了类型Binary的元数据,然后才是那些满足Stringer接口的函数指针列表,在这个例子中就只有一个String方法,而Binary的其它方法则不会在itable中出现。
第二个字节中的指针则指向b的一个副本。下面这个赋值语句 var s Stringer = b 将会申请一个b的副本,并将第二个字节中的指针指向该副本,其原理和 var c unit64 = b 一样。当我们改变b的值的时候,s和c的值将不会被改变。在接口中存储的值可能是任意大小的,但是接口本身却只有一个字来存储数据,所以程序会在堆上申请一组内存来存储该数据,然后再将第二个字上的指针指向该内存组。(如果数据的大小刚才等于或小于一个字,我们在后面会讨论该情况)
像上面的switch语句所进行的特定类型检查,go编译器会生成相当于C中 s.tag->type这样的代码来检查实际类型和期望类型是否相同,如果相同的话,那么s.data将被拷贝并赋值给期望值。
当调用s.String()时,Go编译器生成相当于C语言中的 s.tab->fun[0](s.data)它调用了函数指针指向的方法,并将接口第二个字作为第一个参数传递进去。值得注意的是,它传递的是第二个字中的32位的指针的值,而不是指针所指向的那个64位的值。一般情况下,接口调用并不知道该字节代表什么也不知道它所指向的数据有多大。而方法调用时会严格尊守itable里面所存储的函数指针的签名,因此在本例中该方法的签名应该是(*Binary) string而不是(Binary) string。
在该示例中只有一个方法,如果有多个方法的时候,在itable表的底部将会有多个函数指针。
Computing the Itable
现在我们了解了itable的结构,但它是怎么生成的呢?go语言的动态类型转换特性决定了它不可能在编译时就生成它,因为会有太多的(interface type和concrete type)组成的对,并且大多数不会被使用到。取而代之的是,编译器会为各个实际类型生成一个类型描述结构,该结构就包含了该类型所实现的方法列表。同样的,编译器也会每个接口类型生成这样一个类型描述结构,它也同样包含了接口方法列表。接口在运行时才会生成itable,通过查找接口的类型描述结构和具体类型的类型描述结构,并且将itable缓存起来,因此,这个计算只会被执行一次。
在我们的例子中,Stringer的类型描述结构中只有一个方法,而Binary中有两个方法。假设接口类型拥有ni个方法,实际类型拥有nt个方法,那么找到它所相互匹配的方法所花费的时间复杂度为O(ni x nt),我们可以能过Map存储它们,然后查找过程中时间复杂度则变成O(ni + nt)。
Memory Optimizations
接口的内存使用在两种情况下可以被优化。
- 如果接口类型是interface{}的情况下,也就是没有任何方法的情况下,itable也就没有存在的必要。在这种情况下,第一个字就可以存储实际类型了:
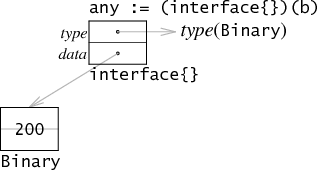
一个接口有没有方法go将用一个静态属性表示,因此编译器知道第一个字表示的是哪一种情况。
- 如果接口所关联的类型的值大小刚好是一个机器字长,那就没有必要进行堆内存的申请了。如果我们像Binary一样定义一个Binary32,将uint32作为它的底层类型,那么它的值就可以直接存储在第二个字中:
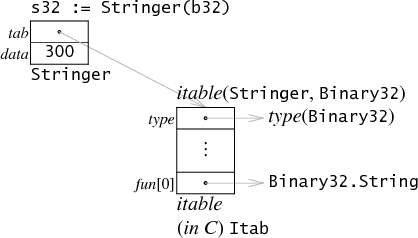
在这种情况下,String的函数签名将变成(Binary) string,而不是原来的(*Binary) string。
因此,当给一个空接口赋值一个大小为一个机器字长的值(或更小)时,它将同时采用上面这两种优化方式。