
引子
在Go 1.13的时候,每当遇到defer语句,运行时就会生成一个_defer结构体对象(结构体保存着延迟函数的地址,参数及参数大小等信息),并将其插入 一个 defer链表的头部(该链表位于当前g上),如下图所示: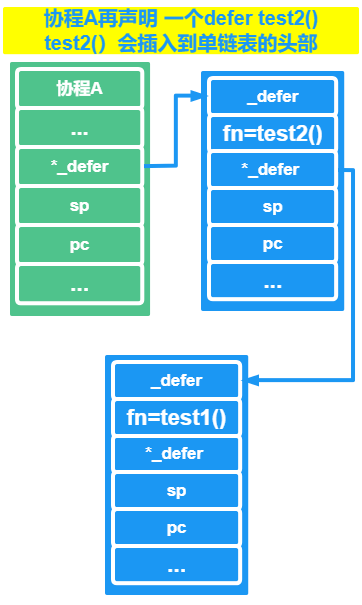
_defer结构体的完整定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// A _defer holds an entry on the list of deferred calls.
// If you add a field here, add code to clear it in freedefer and deferProcStack
// This struct must match the code in cmd/compile/internal/reflectdata/reflect.go:deferstruct
// and cmd/compile/internal/gc/ssa.go:(*state).call.
// Some defers will be allocated on the stack and some on the heap.
// All defers are logically part of the stack, so write barriers to
// initialize them are not required. All defers must be manually scanned,
// and for heap defers, marked.
type _defer struct {
siz int32 // includes both arguments and results
started bool
heap bool
// openDefer indicates that this _defer is for a frame with open-coded
// defers. We have only one defer record for the entire frame (which may
// currently have 0, 1, or more defers active).
openDefer bool
sp uintptr // sp at time of defer
pc uintptr // pc at time of defer
fn *funcval // can be nil for open-coded defers
_panic *_panic // panic that is running defer
link *_defer
// If openDefer is true, the fields below record values about the stack
// frame and associated function that has the open-coded defer(s). sp
// above will be the sp for the frame, and pc will be address of the
// deferreturn call in the function.
fd unsafe.Pointer // funcdata for the function associated with the frame
varp uintptr // value of varp for the stack frame
// framepc is the current pc associated with the stack frame. Together,
// with sp above (which is the sp associated with the stack frame),
// framepc/sp can be used as pc/sp pair to continue a stack trace via
// gentraceback().
framepc uintptr
}
在函数return处,编译器会插入 runtime.deferreturn函数,该函数会从链表头处开始依次执行defer结构体所关联的延迟函数(由于是从头部开始执行,最后的defer语句会最先执行)。由于通过结构体还原运行延迟函数的上下文信息,需要运行时在初期准备一系列延迟函数所需要的上下文环境(参数,调用栈等),因此性能会有一定的损耗(大约35ns,Go 1.12 的50ns,因为1.13将_defer结构体优化到了栈上保存),而如果将这些延迟调用函数在编译时内联展开的话,则只需要大约6ns的时间。因此,Go为了让defer特性不成为性能诟病,在Go 1.14进行了opencoded的优化。
opencoded优化方案
根据 defer 开放代码优化提案 这描述的,我们这里主要看下编译器是如何优化defer性能的。
- 如果一个defer语句处于循环中的话,则无法进行优化。
- 如果defer语句处于条件判断中(如果在编译阶段能计算出条件值的话,则if语句会被直接优化掉)的话,则需要一个defer bit来对其进行标识
条件标志位的逻辑如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24defer f1(a)
if cond {
defer f2(b)
}
body...
==========================================================================================================
deferBits |= 1<<0
tmpF1 = f1
tmpA = a
if cond {
deferBits |= 1<<1
tmpF2 = f2
tmpB = b
}
body...
exit:
if deferBits & 1<<1 != 0 {
deferBits &^= 1<<1
tmpF2(tmpB)
}
if deferBits & 1<<0 != 0 {
deferBits &^= 1<<0
tmpF1(tmpA)
}
简单解释一下,就是在执行defer语句的时候,会将对应的标志位置1,并保存函数指针及其参数。当函数退出前,则会以倒序的方式检测标志位,如果标志为1,则表示需要执行相应的延迟函数,但在执行前,先把对应的标志位归0,然后再调用。
验证
1 | package main |
准备实验代码,将三个延迟函数放入三个条件语句中。
首先看一下不优化是什么情况
go build -gcflags=”-N -l” main.go,-N表示禁止优化 -l表示禁止内联,然后通过gdb查看汇编代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77Dump of assembler code for function main.main:
0x00000000004633e0 <+0>: lea -0x88(%rsp),%r12
0x00000000004633e8 <+8>: cmp 0x10(%r14),%r12
0x00000000004633ec <+12>: jbe 0x46351f <main.main+319>
0x00000000004633f2 <+18>: sub $0x108,%rsp
0x00000000004633f9 <+25>: mov %rbp,0x100(%rsp)
0x0000000000463401 <+33>: lea 0x100(%rsp),%rbp
0x0000000000463409 <+41>: call 0x462e60 <math/rand.Int>
0x000000000046340e <+46>: mov %rax,0x8(%rsp)
0x0000000000463413 <+51>: cmp $0x1f4,%rax
0x0000000000463419 <+57>: jl 0x46341d <main.main+61>
0x000000000046341b <+59>: jmp 0x463463 <main.main+131>
0x000000000046341d <+61>: movl $0x0,0xb0(%rsp)
0x0000000000463428 <+72>: lea 0x19c39(%rip),%rcx # 0x47d068
0x000000000046342f <+79>: mov %rcx,0xc8(%rsp)
0x0000000000463437 <+87>: lea 0xb0(%rsp),%rax
0x000000000046343f <+95>: nop
0x0000000000463440 <+96>: call 0x42b380 <runtime.deferprocStack>
0x0000000000463445 <+101>: test %eax,%eax
0x0000000000463447 <+103>: jne 0x46344d <main.main+109>
0x0000000000463449 <+105>: jmp 0x46344b <main.main+107>
0x000000000046344b <+107>: jmp 0x463465 <main.main+133>
0x000000000046344d <+109>: nop
0x000000000046344e <+110>: call 0x42bfe0 <runtime.deferreturn>
0x0000000000463453 <+115>: mov 0x100(%rsp),%rbp
0x000000000046345b <+123>: add $0x108,%rsp
0x0000000000463462 <+130>: ret
0x0000000000463463 <+131>: jmp 0x463465 <main.main+133>
0x0000000000463465 <+133>: call 0x462e60 <math/rand.Int>
0x000000000046346a <+138>: mov %rax,0x8(%rsp)
0x000000000046346f <+143>: cmp $0x258,%rax
0x0000000000463475 <+149>: jl 0x463479 <main.main+153>
0x0000000000463477 <+151>: jmp 0x4634b5 <main.main+213>
0x0000000000463479 <+153>: movl $0x0,0x60(%rsp)
0x0000000000463481 <+161>: lea 0x19be8(%rip),%rcx # 0x47d070
0x0000000000463488 <+168>: mov %rcx,0x78(%rsp)
0x000000000046348d <+173>: lea 0x60(%rsp),%rax
0x0000000000463492 <+178>: call 0x42b380 <runtime.deferprocStack>
0x0000000000463497 <+183>: test %eax,%eax
0x0000000000463499 <+185>: jne 0x46349f <main.main+191>
0x000000000046349b <+187>: jmp 0x46349d <main.main+189>
0x000000000046349d <+189>: jmp 0x4634b7 <main.main+215>
0x000000000046349f <+191>: nop
0x00000000004634a0 <+192>: call 0x42bfe0 <runtime.deferreturn>
0x00000000004634a5 <+197>: mov 0x100(%rsp),%rbp
0x00000000004634ad <+205>: add $0x108,%rsp
0x00000000004634b4 <+212>: ret
0x00000000004634b5 <+213>: jmp 0x4634b7 <main.main+215>
0x00000000004634b7 <+215>: call 0x462e60 <math/rand.Int>
0x00000000004634bc <+220>: mov %rax,0x8(%rsp)
0x00000000004634c1 <+225>: cmp $0x2bc,%rax
0x00000000004634c7 <+231>: jl 0x4634cb <main.main+235>
0x00000000004634c9 <+233>: jmp 0x463507 <main.main+295>
0x00000000004634cb <+235>: movl $0x0,0x10(%rsp)
0x00000000004634d3 <+243>: lea 0x19b9e(%rip),%rcx # 0x47d078
0x00000000004634da <+250>: mov %rcx,0x28(%rsp)
0x00000000004634df <+255>: lea 0x10(%rsp),%rax
0x00000000004634e4 <+260>: call 0x42b380 <runtime.deferprocStack>
0x00000000004634e9 <+265>: test %eax,%eax
0x00000000004634eb <+267>: jne 0x4634f1 <main.main+273>
0x00000000004634ed <+269>: jmp 0x4634ef <main.main+271>
0x00000000004634ef <+271>: jmp 0x463509 <main.main+297>
0x00000000004634f1 <+273>: nop
0x00000000004634f2 <+274>: call 0x42bfe0 <runtime.deferreturn>
0x00000000004634f7 <+279>: mov 0x100(%rsp),%rbp
0x00000000004634ff <+287>: add $0x108,%rsp
0x0000000000463506 <+294>: ret
0x0000000000463507 <+295>: jmp 0x463509 <main.main+297>
0x0000000000463509 <+297>: nop
0x000000000046350a <+298>: call 0x42bfe0 <runtime.deferreturn>
0x000000000046350f <+303>: mov 0x100(%rsp),%rbp
0x0000000000463517 <+311>: add $0x108,%rsp
0x000000000046351e <+318>: ret
0x000000000046351f <+319>: nop
0x0000000000463520 <+320>: call 0x4554c0 <runtime.morestack_noctxt>
0x0000000000463525 <+325>: jmp 0x4633e0 <main.main>
End of assembler dump.
这里可以看到 96,178,260处均调用了runtime.deferprocStack,此函数将会构造_defer结构体并加入defer链表。
再来看一下优化后的代码是什么情况:go build main.go,(不加 -gcflags=”-N -l”参数),优化后的汇编代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130Dump of assembler code for function main.main:
栈检查,不够则跳转至动态扩容处
==============================================================================================
0x0000000000463300 <+0>: cmp 0x10(%r14),%rsp
0x0000000000463304 <+4>: jbe 0x46340f <main.main+271>
main函数栈帧40字节
==============================================================================================
0x000000000046330a <+10>: sub $0x30,%rsp # 栈顶调整
0x000000000046330e <+14>: mov %rbp,0x28(%rsp) # 保存栈底旧值
0x0000000000463313 <+19>: lea 0x28(%rsp),%rbp # 栈底调整
==============================================================================================
0x0000000000463318 <+24>: movups %xmm15,0x10(%rsp)
0x000000000046331e <+30>: movups %xmm15,0x18(%rsp)
==============================================================================================
0x0000000000463324 <+36>: movb $0x0,0x7(%rsp) # 0x7(第8个字节)处,置0,该字节为 defer bit
第一个if, if 500 > rand.Int(), 如果随机数大于等于500,则直接跳转至76行
==============================================================================================
0x0000000000463329 <+41>: call 0x462d80 <math/rand.Int>
0x000000000046332e <+46>: mov %rax,0x8(%rsp)
0x0000000000463333 <+51>: cmp $0x1f4,%rax
0x0000000000463339 <+57>: jge 0x46334c <main.main+76>
==============================================================================================
0x000000000046333b <+59>: lea 0x19d16(%rip),%rcx # 0x47d058
0x0000000000463342 <+66>: mov %rcx,0x20(%rsp)
将defer bit 第一位置1
==============================================================================================
0x0000000000463347 <+71>: movb $0x1,0x7(%rsp) # 0x7处的值为 00000001
第二个if, if 600 > rand.Int()
==============================================================================================
0x000000000046334c <+76>: call 0x462d80 <math/rand.Int>
0x0000000000463351 <+81>: mov 0x8(%rsp),%rcx # 注意0x8留存的是第一个rand的结果(46行)
0x0000000000463356 <+86>: cmp $0x1f4,%rcx # 这里又进行一次和(500)的比较,是不是还有优化的空间?
0x000000000046335d <+93>: setl %cl # 如果rcx小于500,则cl置为1
0x0000000000463360 <+96>: cmp $0x258,%rax # 第二个rand的值和600比较
0x0000000000463366 <+102>: jge 0x46337b <main.main+123> # 如果大于等于600则直接跳至123行
==============================================================================================
0x0000000000463368 <+104>: lea 0x19cf1(%rip),%rax # 0x47d060
0x000000000046336f <+111>: mov %rax,0x18(%rsp)
将第二个bit位置1
==============================================================================================
0x0000000000463374 <+116>: or $0x2,%ecx # exc = 00000010 | ecx
0x0000000000463377 <+119>: mov %cl,0x7(%rsp) # 0x7 存储defer bit
0x000000000046337b <+123>: mov %cl,0x6(%rsp) # 0x6 存储defer bit
第三个if, if 700 > rand.Int()
==============================================================================================
0x000000000046337f <+127>: nop
0x0000000000463380 <+128>: call 0x462d80 <math/rand.Int>
0x0000000000463385 <+133>: cmp $0x2bc,%rax
0x000000000046338b <+139>: jge 0x4633a7 <main.main+167>
==============================================================================================
0x000000000046338d <+141>: lea 0x19cd4(%rip),%rax # 0x47d068
0x0000000000463394 <+148>: mov %rax,0x10(%rsp)
将第三个bit位置1
==============================================================================================
0x0000000000463399 <+153>: movzbl 0x6(%rsp),%ecx # 移动8(b)位至32(l)位,高24位用0(z:zero)补齐
0x000000000046339e <+158>: or $0x4,%ecx # ecx = 00000100 | ecx
0x00000000004633a1 <+161>: mov %cl,0x7(%rsp) # 此时 0x7保存着defer bit标识着三个if都进行了处理了
0x00000000004633a5 <+165>: jmp 0x4633ac <main.main+172>
==============================================================================================
0x00000000004633a7 <+167>: movzbl 0x6(%rsp),%ecx # 移动8(b)位至32(l)位,高24位用0(z:zero)补齐
如果第3个bit为0,则跳过dwrap·3的调用
==============================================================================================
0x00000000004633ac <+172>: test $0x4,%cl
0x00000000004633af <+175>: je 0x4633ca <main.main+202>
调用main.main·dwrap·3
==============================================================================================
0x00000000004633b1 <+177>: and $0xfffffffb,%ecx # ecx = 1011 & ecx 执行之前先将第3位置0
0x00000000004633b4 <+180>: mov %cl,0x6(%rsp) # 0x6 保存 defer bit
0x00000000004633b8 <+184>: mov %cl,0x7(%rsp) # 0x7 保存 defer bit
0x00000000004633bc <+188>: nopl 0x0(%rax)
0x00000000004633c0 <+192>: call 0x463500 <main.main·dwrap·3>
0x00000000004633c5 <+197>: movzbl 0x6(%rsp),%ecx
如果第2个bit为0,则跳过dwrap·2的调用
==============================================================================================
0x00000000004633ca <+202>: test $0x2,%cl
0x00000000004633cd <+205>: je 0x4633e4 <main.main+228>
调用main.main·dwrap·2
==============================================================================================
0x00000000004633cf <+207>: and $0xfffffffd,%ecx # ecx = 1101 & ecx 执行之前先将第2位置0
0x00000000004633d2 <+210>: mov %cl,0x6(%rsp) # 0x6 保存 defer bit
0x00000000004633d6 <+214>: mov %cl,0x7(%rsp) # 0x7 保存 defer bit
0x00000000004633da <+218>: call 0x4634a0 <main.main·dwrap·2>
0x00000000004633df <+223>: movzbl 0x6(%rsp),%ecx
如果第1个bit为0,则跳过dwrap·1的调用
==============================================================================================
0x00000000004633e4 <+228>: test $0x1,%cl
0x00000000004633e7 <+231>: je 0x4633f5 <main.main+245>
调用main.main·dwrap·1
==============================================================================================
0x00000000004633e9 <+233>: and $0xfffffffe,%ecx # ecx = 1110 & ecx 执行之前先将第1位置0
0x00000000004633ec <+236>: mov %cl,0x7(%rsp) # 0x7 保存 defer bit
0x00000000004633f0 <+240>: call 0x463440 <main.main·dwrap·1>
main函数返回
==============================================================================================
0x00000000004633f5 <+245>: mov 0x28(%rsp),%rbp # 栈底调整
0x00000000004633fa <+250>: add $0x30,%rsp # 栈顶调整
0x00000000004633fe <+254>: ret
==============================================================================================
0x00000000004633ff <+255>: nop
0x0000000000463400 <+256>: call 0x42bf20 <runtime.deferreturn>
==============================================================================================
0x0000000000463405 <+261>: mov 0x28(%rsp),%rbp
0x000000000046340a <+266>: add $0x30,%rsp
0x000000000046340e <+270>: ret
==============================================================================================
0x000000000046340f <+271>: call 0x455400 <runtime.morestack_noctxt>
0x0000000000463414 <+276>: jmp 0x463300 <main.main>
End of assembler dump.
我们看一下main函数的执行逻辑,从以上代码可以看出,在0x7这个位置的字节上,保存的应该就是我们提到的defer bit标志数据。这里我们并没有看到runtime.deferproc或者是runtime.deferprocStack调用,表明延迟函数确实被编译时展开了。而每个条件判断成立时,则会设置相应的标志位,我们以第二个条件为例:
1
20x0000000000463360 <+96>: cmp $0x258,%rax # 第二个rand的值和600比较
0x0000000000463366 <+102>: jge 0x46337b <main.main+123> # 如果大于等于600则直接跳至123行
可以看到如果随机数大于等于600时,则会跳过第二个bit的设置:(116行),则该位的值还是01
2
30x0000000000463374 <+116>: or $0x2,%ecx # exc = 00000010 | ecx
0x0000000000463377 <+119>: mov %cl,0x7(%rsp) # 0x7 存储defer bit
0x000000000046337b <+123>: mov %cl,0x6(%rsp) # 0x6 存储defer bit
疑问:为啥这里还要有一个0x6来保存一下defer bit?
而接下来,在函数ret前,被插入的代码则是以倒序的方式检测每个标志位 0x4->0x2->0x1, 看下0x2标志位是如何检测的:1
20x00000000004633ca <+202>: test $0x2,%cl
0x00000000004633cd <+205>: je 0x4633e4 <main.main+228>
此时cl保存着defer bit,test指令将两个操作数执行逻辑与操作,如果cl的第二位为1,则zf寄存器则为0,则je条件不成立,则不会进行跳转,因为接下来的指令正是对第二个延迟函数的调用:1
2
3
4
50x00000000004633cf <+207>: and $0xfffffffd,%ecx # ecx = 1101 & ecx 执行之前先将第2位置0
0x00000000004633d2 <+210>: mov %cl,0x6(%rsp) # 0x6 保存 defer bit
0x00000000004633d6 <+214>: mov %cl,0x7(%rsp) # 0x7 保存 defer bit
0x00000000004633da <+218>: call 0x4634a0 <main.main·dwrap·2>
0x00000000004633df <+223>: movzbl 0x6(%rsp),%ecx
在真正的调用之前,会先将第二个bit置成0。然后在218处调用main.main·dwrap·2函数,我们再展开该函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39Dump of assembler code for function main.main·dwrap·2:
栈检查,不够则跳转至动态扩容处
==============================================================================================
0x0000000000463440 <+0>: cmp 0x10(%r14),%rsp
0x0000000000463444 <+4>: jbe 0x46346e <main.main·dwrap·2+46>
main.main·dwrap·2 栈帧 0字节
==============================================================================================
0x0000000000463446 <+6>: sub $0x8,%rsp # 调整栈顶
0x000000000046344a <+10>: mov %rbp,(%rsp) # 保留栈底旧值
0x000000000046344e <+14>: lea (%rsp),%rbp # 栈底调整
==============================================================================================
0x0000000000463452 <+18>: mov 0x20(%r14),%r12
0x0000000000463456 <+22>: test %r12,%r12
0x0000000000463459 <+25>: jne 0x463475 <main.main·dwrap·2+53> # r12 > 0
==============================================================================================
0x000000000046345b <+27>: nopl 0x0(%rax,%rax,1)
0x0000000000463460 <+32>: call 0x463420 <main.named>
回收 main.main·dwrap·2 栈帧
==============================================================================================
0x0000000000463465 <+37>: mov (%rsp),%rbp
0x0000000000463469 <+41>: add $0x8,%rsp
0x000000000046346d <+45>: ret
==============================================================================================
0x000000000046346e <+46>: call 0x455400 <runtime.morestack_noctxt>
0x0000000000463473 <+51>: jmp 0x463440 <main.main·dwrap·2>
==============================================================================================
0x0000000000463475 <+53>: lea 0x10(%rsp),%r13
0x000000000046347a <+58>: nopw 0x0(%rax,%rax,1)
0x0000000000463480 <+64>: cmp %r13,(%r12)
0x0000000000463484 <+68>: jne 0x46345b <main.main·dwrap·2+27>
0x0000000000463486 <+70>: mov %rsp,(%r12)
0x000000000046348a <+74>: jmp 0x46345b <main.main·dwrap·2+27>
End of assembler dump.
可以看到,无论何种情况,都会最终调用真正的main.named这个函数
- 25 -> 53 -> 68 -> 27 -> 32(main.named)
- 25 -> 53 -> 74 -> 27 -> 32(main.named)
- 25 -> 27 -> 32(main.named)
最后展开main.named,看到确实是 return 1(通过eax寄存器返回)1
2
3
4Dump of assembler code for function main.named:
0x0000000000463420 <+0>: mov $0x1,%eax
0x0000000000463425 <+5>: ret
End of assembler dump.
总结
标志位的变化
最后我们来看一下defer bit标志位数据变化的情况,我们假设三个if条件全部成立:
0000 -> rand.Int() -> 0001 -> rand.Int() -> 0011 -> rand.Int() -> 0111 -> named() -> 0011 -> named() -> 0001 -> named() -> 0000
免去defer链表递归调用
从实验代码可以看出,优化后的代码并没有出现runtime.deferproc或runtime.deferprocStack调用,最后函数返回时,也跳过了runtime.deferreturn的调用,我们知道一旦进入defer链表的递归调用(runtime.jmpdefer 尾递归)后,因为维护延迟函数的上下文环境需要花费非常多的指令,(defer结构体的创建和销毁等操作)这也是早期Go版本的defer特性被人诟病性能低下的重要原因。
经过开放代码优化后,我们可以看到这和直接调用函数的性能相差无几(多了标志位的维护),当然这里我们还可以看到deferbit只有一个字节也就是8位,因此我们最多支持8个defer语句,超过8将会回到defer链表模式(循环中的defer无法优化)。
(实验环境go1.17.2 linux/amd64)